

XAI has officially unveiled Grok 4, its latest artificial intelligence model, presenting it as a significant leap forward in AI capabilities and intelligence. The announcement, featuring Elon Musk and other XAI team members, highlighted the model’s performance across various benchmarks and its potential for diverse real-world applications. The introduction of Grok 4 benchmarks is poised to reshape the competitive landscape of large language models, challenging existing industry leaders with its advanced reasoning and massive training infrastructure.
The presentation positioned Grok 4 as the “smartest AI in the world”, a claim backed by impressive results on standardized tests and complex problem-solving scenarios. This new iteration represents a substantial investment in compute power and a commitment to developing an AI that can tackle sophisticated challenges across multiple disciplines.
Table of Contents
Grok 4 Benchmarks: A Comparative Analysis
XAI provides a comprehensive comparison of Grok 4’s performance against leading competitor models, including Gemini and Claude, across several key benchmarks. The results highlight Grok 4’s strong capabilities, particularly in mathematics and reasoning tasks. The data specifically compares Grok 4 (without tools) and Grok 4 Heavy against competitors such as Gemini 2.5 Pro, Claude 4 Opus, and other models labeled ‘o3’ and ‘Gemini Deep Think’.
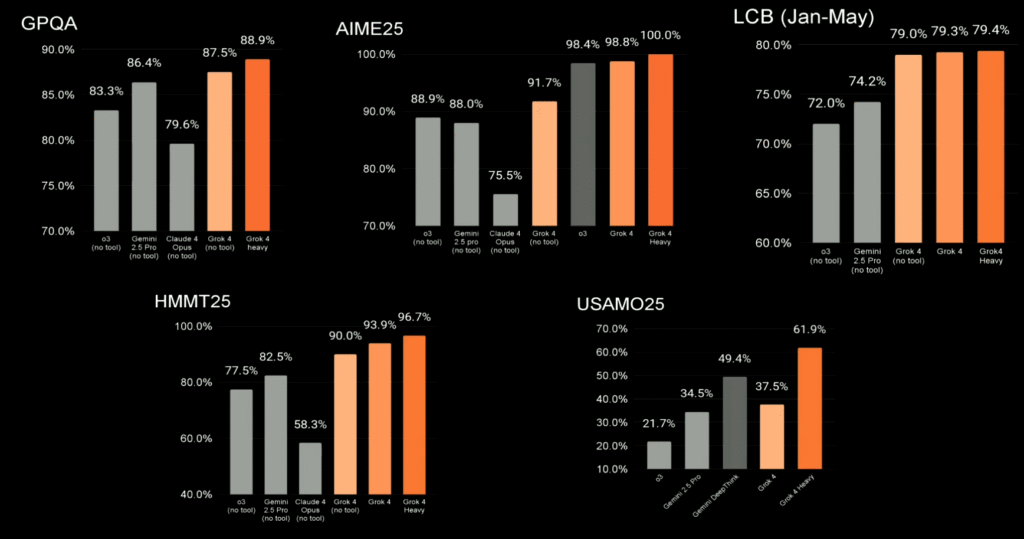
Performance Across Key Disciplines
The comparative analysis shows Grok 4 models achieving top results in highly competitive areas:
- GPQA (General Purpose Question Answering): Grok 4 achieved an 87.5% score, while Grok 4 Heavy reached 88.9%. Both models outperformed Gemini 2.5 Pro (86.4%), Claude 4 Opus (79.6%), and o3 (83.3%).
- AIME25 (American Invitational Mathematics Examination): Grok 4 demonstrated exceptional mathematical proficiency with a 98.4% score. Notably, Grok 4 Heavy achieved a perfect 100.0%. Competitors lagged significantly, with Gemini 2.5 Pro at 88.0%, Claude 4 Opus at 75.5%, and o3 at 88.9%.
- HMMT25 (Harvard-MIT Mathematics Tournament): Grok 4 scored 93.9% and Grok 4 Heavy scored 96.7%. This places Grok 4 models substantially ahead of o3 (82.5%), Gemini 2.5 Pro (77.5%), and Claude 4 Opus (58.3%).
USAMO25 and LCB Benchmarks
Grok 4 also showed strong results in more specialized areas:
- USAMO25 (USA Mathematical Olympiad): In this highly complex benchmark, Grok 4 Heavy led with a score of 61.9%. Grok 4 (no tool) scored 37.5%, while competitors Gemini Deep Think and Gemini 2.5 Pro scored 34.5% and 21.7% respectively.
- LCB (Language and Coding Benchmark, Jan-May): Grok 4 Heavy recorded a 79.4% score, slightly above Grok 4’s 79.0%. These results demonstrate strong performance in coding and language tasks compared to competitors like Gemini 2.5 Pro (74.2%) and Claude 4 Opus (79.3%).
The consistent high performance of Grok 4 and Grok 4 Heavy across these varied benchmarks underscores XAI’s claims regarding the model’s intelligence and efficacy in complex problem-solving.
Grok 4 Intelligence and Reasoning
The core of the Grok 4 announcement centered on its claimed intelligence and reasoning abilities. XAI reported that Grok 4 has achieved perfect scores on standardized tests such as the SAT and near-perfect scores on graduate-level exams (GRE) across all disciplines. These results were achieved even with questions the model had not encountered during its training. This performance led to the assertion that the model is “smarter than almost all graduate students in all disciplines simultaneously.”
The model’s capabilities extend to the “Humanities Last Exam” (HLE), a rigorous benchmark comprising problems curated by PhD-level subject matter experts. It also demonstrated the ability to solve a substantial portion of these highly challenging problems, particularly when utilizing its enhanced tool-using capabilities and the Grok 4 Heavy approach.

Training, Compute, and Grok 4 Heavy Architecture
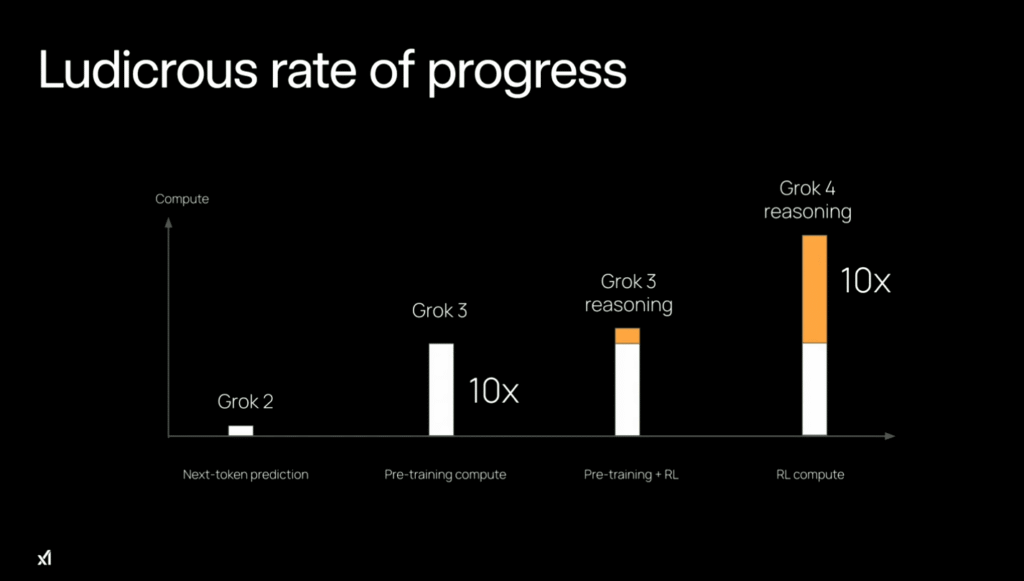
The development of this latest model involved a significant scaling of training and compute resources. XAI emphasized that the training for Grok 4 was 100 times more extensive than that of Grok 2. This massive undertaking utilized the Colossus supercomputer, equipped with 100,000 H100 GPUs. Furthermore, the model benefited from a 10x increase in compute dedicated to reinforcement learning (RL) compared to other models on the market.
A key architectural innovation is the Grok 4 Heavy model. This approach involves spawning multiple independent agents to work on a problem simultaneously. These agents then compare their findings and collaborate, akin to a “study group,” to determine the optimal solution. This multi-agent system aims to enhance the model’s accuracy and robustness.
Grok 4 also features significantly enhanced tool-using capabilities. Unlike Grok 3, which relied on generalization, this model integrates tool use directly into its training. This allows the model to leverage external tools for complex problem-solving, although current tools are described as primitive compared to future developments.
Real-World Applications and Demonstrations
The presentation showcased the models versatility through various real-world applications. Demonstrations included the model’s ability to predict outcomes, such as World Series odds on platforms like Poly Market, and its capacity to generate visualizations, including simulations of black holes colliding. This latest model also demonstrated seamless interaction with X (formerly Twitter) for information retrieval, such as finding specific employee profile photos or tracking the timeline of HLE scores.
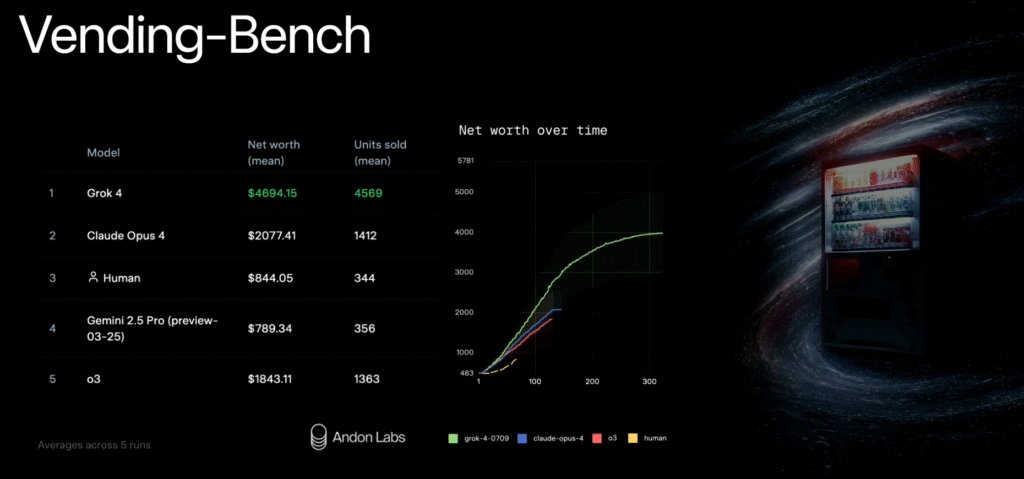
In a business context, the model showed top performance on “Vending Bench,” an AI simulation designed to test the management of a vending machine business. The model is also being utilized in biomedical research, with organizations like the ARC Institute using it to analyze experiment logs. A notable demonstration highlighted the models role in video game creation, showcasing a first-person shooter developed in just four hours by using the AI to source assets.
Voice Mode and API Availability
Significant improvements have been made to Grok’s voice mode. The latency has been halved, and new, more natural-sounding voices, such as “Saul” and “Eve,” have been introduced. A live demo featured “Eve” singing an opera about Diet Coke, demonstrating the model’s improved emotional range and naturalness.
The new model is now available via API, featuring a 256k context length, which enables developers to integrate the model into their applications. The API demonstrated strong performance on the RKGI benchmark, facilitating the development of sophisticated AI tools.

Future Directions and Safety
XAI outlined ambitious future directions for the model and subsequent models. While current weaknesses include image understanding and generation, these are being addressed with the upcoming version 7 of their foundation model. A specialized, fast, and smart coding model is also in development. Major improvements are expected in multimodal capabilities, allowing the model to “hear and see the world” through enhanced image, video, and audio understanding.
Training for a video generation model is expected to begin soon, leveraging over 100,000 GB200s, with the goal of achieving “pixel in, pixel out” capabilities and interactive content. XAI also emphasized a core safety principle: making AI “maximally truth-seeking.”